
6 lý do mà Postgres database của CloudFlare đã xử lý được 55 triệu RPS
Tìm hiểu cách CloudFlare đã thiết kế hệ thống phục vụ tải lớn

Khoảng những năm cuối của thập niên 2000, CDN (Content Delivery Network) nổi lên như một làn sóng công nghệ mới giúp tăng tốc độ của các website.
Nắm bắt làn sóng đó, vào tháng 7 năm 2009, ở bang California Mỹ, một nhóm sinh viên ở đại học Harvard đã cùng nhau cho ra đời một nền tảng CDN mới, tên là CloudFlare.
Dù sinh sau đẻ muộn, nhưng CloudFlare đã nhanh chóng chiếm lĩnh thị trường CDN nói riêng và traffic mạng Internet nói chung.
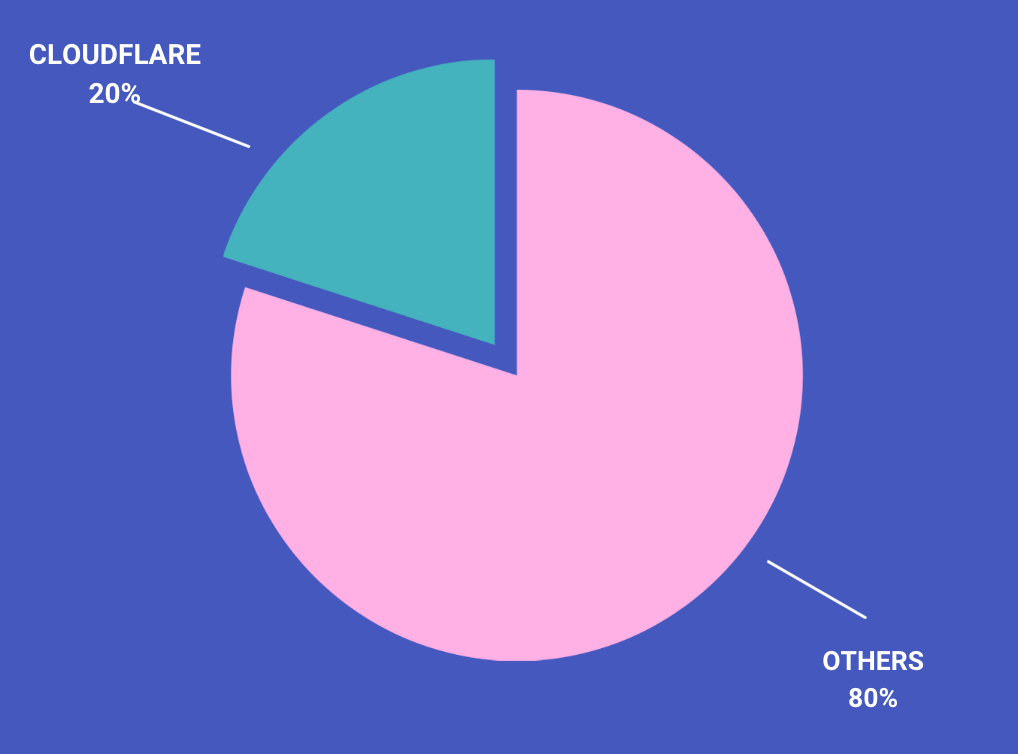
Tính đến năm 2023, có tới 20% traffic trên toàn bộ Internet đi qua hệ thống hạ tầng của CloudFlare. Với số lượng Request Per Second (RPS) lên tới 55 triệu HTTP requests / giây.
Và thật đáng ngạc nhiên khi CloudFlare giải quyết bài toán OLTP (Online Transaction Processing) chỉ với 15 Postgres clusters.
Mỗi cluster gồm ba server. Mỗi server nằm ở một khu vực khác nhau (region) để đảm bảo khả năng recovery khi có disaster.
Vậy CloudFlare đã tuning những gì để Postgres có thể handle một lượng traffic lớn đến như thế, chúng ta cùng bắt đầu tìm hiểu.
1. Connection Pool
Thông thường khả năng xử lý của database thường bị giới hạn bởi các resources có hạn như CPU, Memory.
Một giới hạn nữa là số connections, vì sao vậy?
Trong Postgres, mỗi request từ client tới sẽ tạo ra một process mới. Mà số lượng process cũng là hữu hạn (vì phụ thuộc vào CPU, Memory). Nên số connections cũng là hữu hạn.
Vậy muốn tăng số lượng connections lên nữa thì phải làm sao? Câu trả lời là dùng một connection pool đứng giữa.
Connection pool là một technique thường được dùng để optimize hiệu năng khi số lượng connection vượt quá khả năng handle của server.
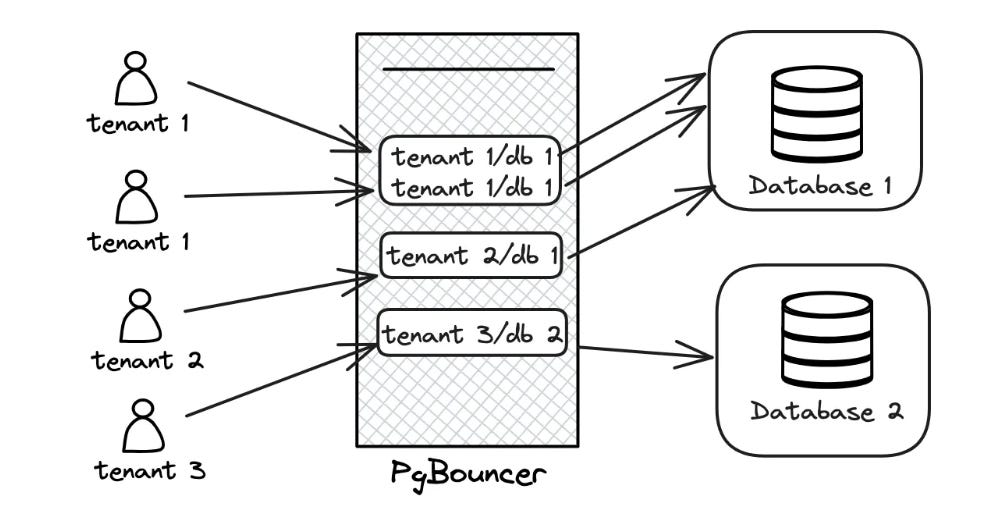
PgBouncer, bản chất là TCP Proxy, đứng giữa để quản lý connection từ phía client. Khi này client sẽ tạo connection với PgBouncer thay vì Postgres.
PgBouncer có vài tác dụng chính như:
Bảo vệ Postgres Server khỏi connection starvation
Tiết kiệm Postgres Server resource khi reuse connection
Throttle những câu query chạy quá lâu
2. Bare metal
Để tránh việc phải chạy trên nhiều tầng ảo hoá (virtualization), Cloudflare không chạy Postgres trên môi trường cloud.
Thay vào đó họ chạy các cụm Postgres server trên những server vật lý (Bare metal).
3. HA Proxy làm Load Balancer
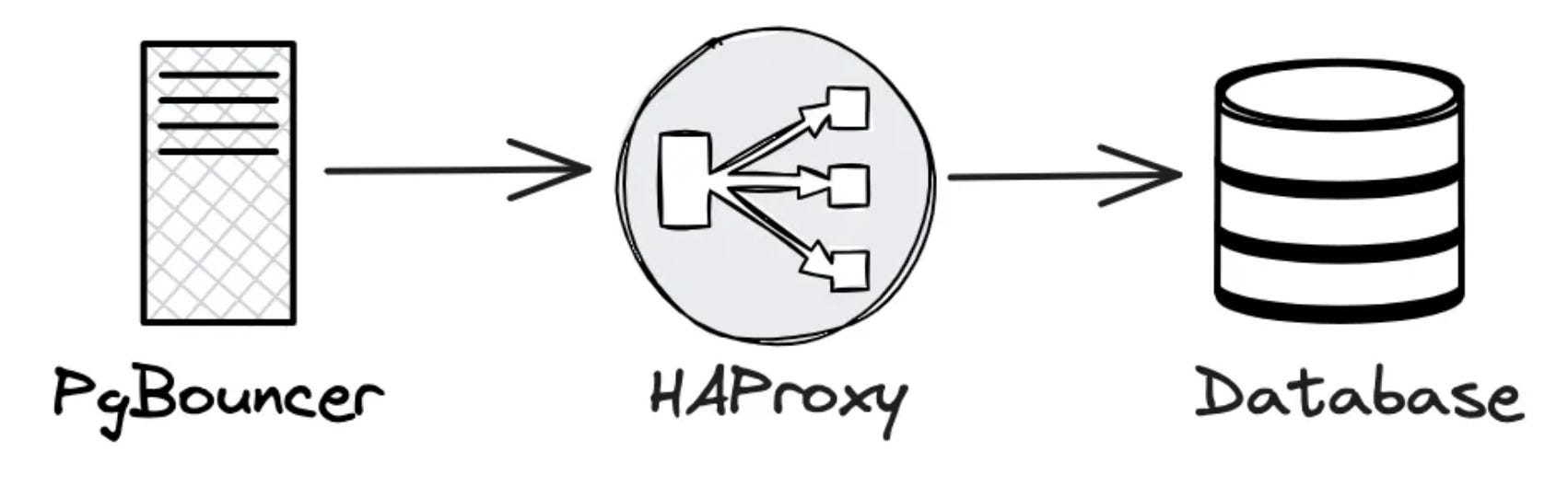
Theo lý thuyết thì PgBouncer hoàn toàn có thể đóng vai trò của load balancer. Tuy nhiên, load balancer không phải là tính năng chính nên nếu dùng sẽ không tốt cho hiệu năng (performance).
Do đó, CloudFlare đã dùng HAProxy làm TCP proxy đứng giữa PgBouncer và Postgres server.
4. Concurrency
Congestion (tắc nghẽn) là một vấn đề xảy ra với mọi mô hình client-server. Chẳng hạn như TCP, cũng có thuật toán riêng để xử lý tắc nghẽn, gọi là TCP congestion avoidance.
PgBouncer và Postgres Server cũng áp dụng ý tưởng này để xử lý vấn đề tắc nghẽn.
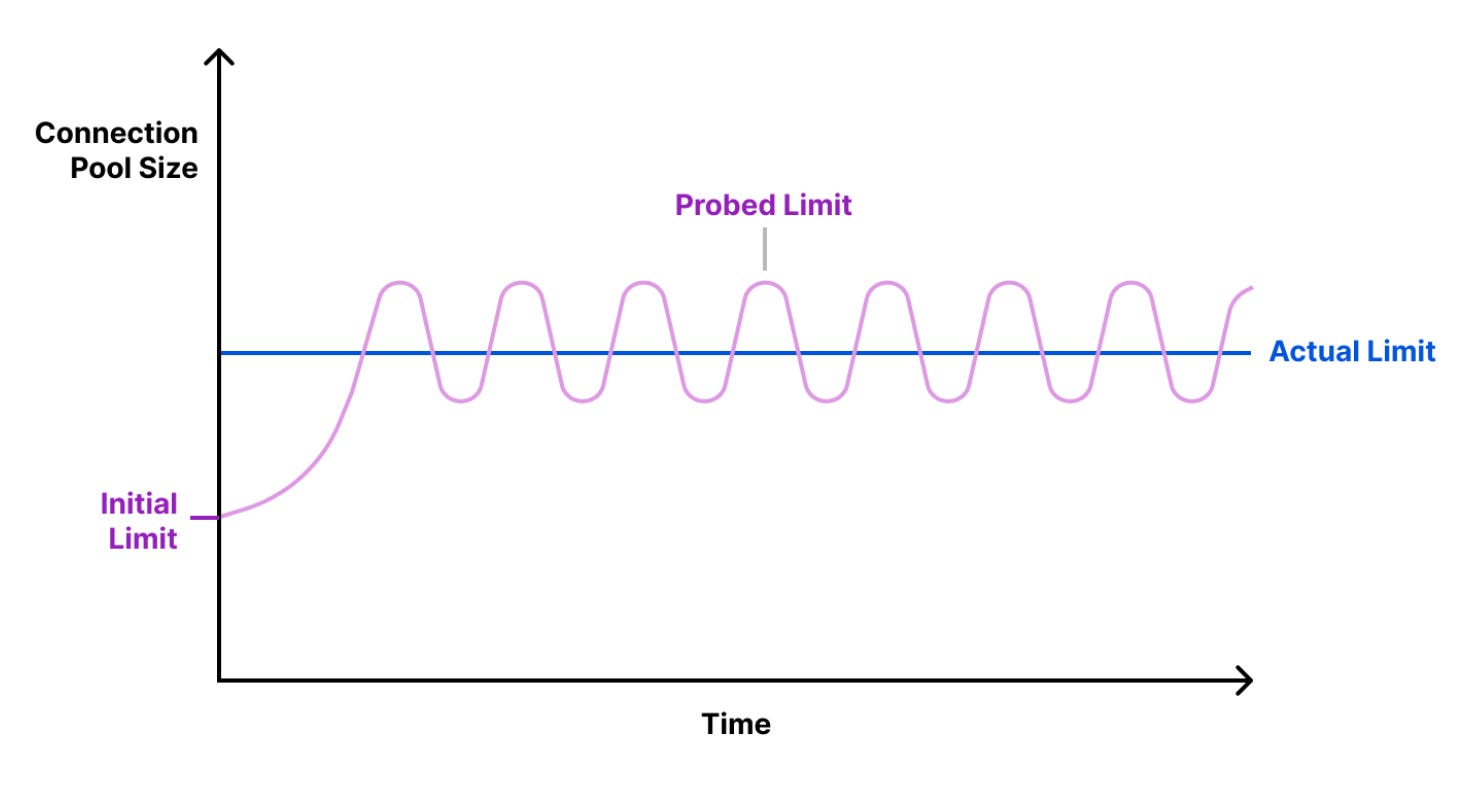
Khi bắt đầu, PgBouncer sẽ tạo một lượng connection pool đủ nhỏ. Sau đó số lượng connection trong pool tăng dần. PgBouncer sẽ đo xem mỗi khi tăng số connection đến với server, thì thời gian phản hồi (Round Time Trip - RTT) có được đảm bảo hay không. Nếu vẫn được đảm bảo, số connection sẽ tăng tiếp, còn không số connection sẽ giảm cho đến khi RTT đạt được con số mong muốn.
5. Ordering Queries
Mỗi câu query tới với PgBouncer sẽ được đưa vào một prioritized queue. Dựa trên yếu tố lịch sử, nếu câu query chạy càng lâu thì độ ưu tiên càng thấp.
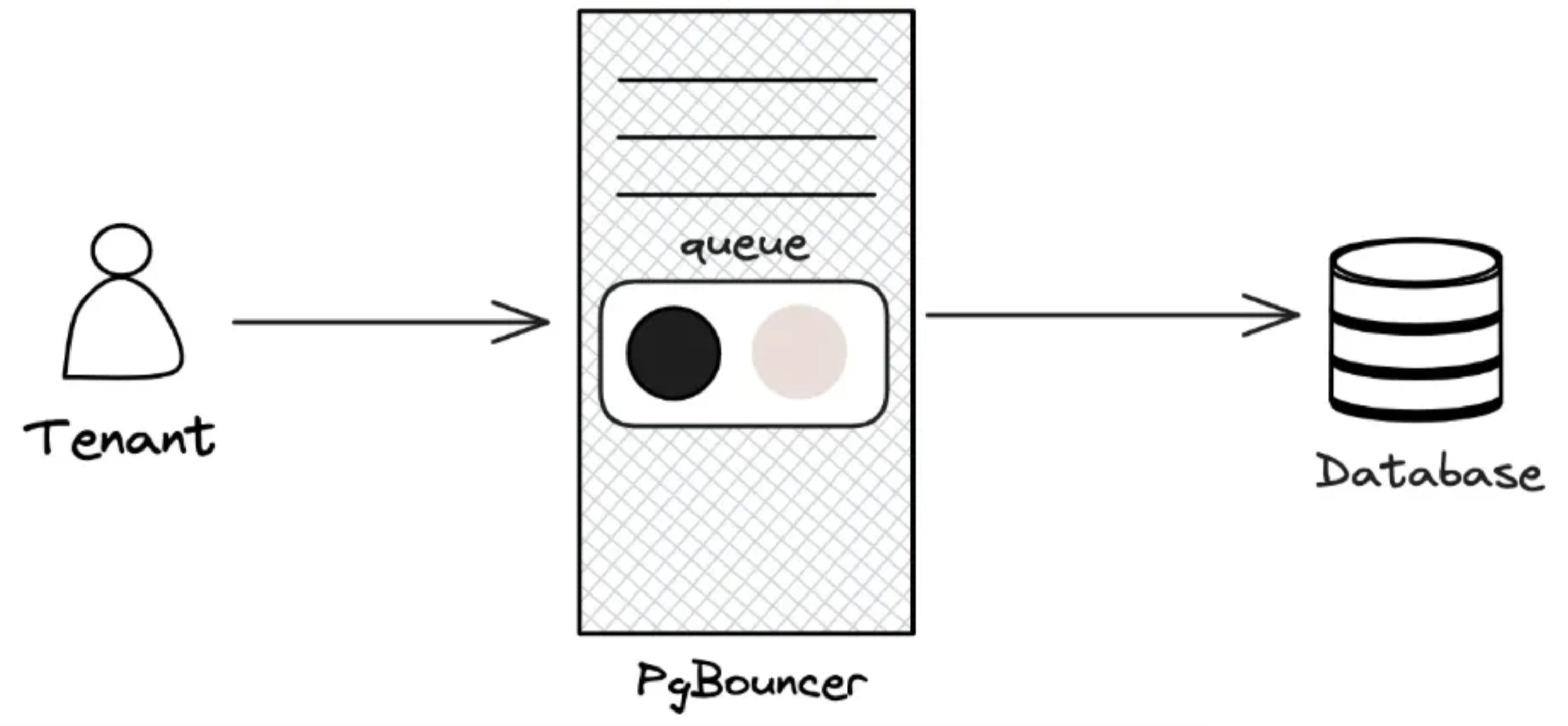
Tuy nhiên, sẽ có thể có trường hợp những câu query có độ ưu tiên thấp hơn sẽ không bao giờ được thực thi. Tình trạng này gọi là resource starvation.
Để giải quyết vấn đề này, PgBouncer chỉ enable prioritized queue trong peak traffic. Tức là khi có traffic bình thường thì mọi câu query sẽ đều được execute.
6. High availability
Thông thường khi nói về tính sẵn sàng của một hệ thống (HA - High Availability), thông số đại diện sẽ là uptime - tức thời gian hệ thống up and running.
Khi dùng một SaaS, bên cung cấp dịch vụ sẽ phải đưa ra một cái SLA (Service Level Agreement) để cam kết trong một năm thời gian uptime tối thiểu là bao nhiêu.
Ví dụ, GKE (Google Kubernetes Engine) cam kết thời gian uptime là 99,5%. Điều đó có nghĩa trong một năm, hệ thống của họ “được phép” bị sập khoảng 0,5% x 365d = 1d 19h 28m 8.8s, hoặc mỗi ngày sẽ có thể sập 7m 12s.
Quay trở lại với cụm Postgres cluster của CloudFlare. Họ dùng Stolon để đảm bảo tính HA.

Stolon có vài nhiệm vụ:
Đảm bảo data sẽ được replicate sang các server trong cùng cluster mà nó đang quản lý
Thực hiện failover. Tức khi leader database gặp vấn đề, stolon sẽ đứng ra thực hiện election (bầu cử), và chọn ra leader server mới từ nhóm follower server.
Nếu bạn thấy bài viết này hữu ích, hãy nhập email để đăng kí thành viên để không bỏ lỡ những bài viết mới của tôi nhé 💪
Trích dẫn
Performance isolation in a multi-tenant database environment, blog.cloudflare.com
CloudFlare internet traffic 2023, theregister.com
PostgresSQL Scalability, Neokim
bài viết hay, cảm ơn tác giả :D